Hva er ditt forskningsfelt?
Forskergruppen vår, Computational Biology & Gene Regulation, arbeider innenfor feltet beregningsorientert biologi, av og til også kalt bioinformatikk.

Kort sagt utvikler og vurderer vi beregningsmetoder for analyse av genomiske sekvenser (DNA). Jeg er utdannet informatiker og har i tillegg tilegnet meg en sterk forståelse av den underliggende biologien. Jeg kan dermed bruke min kunnskap både innen informatikk og biologi til å utvikle programvare som forskningsmiljøet kan ha nytte av.
Gruppen vår har som mål å skape neste generasjon banebrytende algoritmer og åpen programvare innen beregningsorientert biologi med direkte anvendelse på reelle biologiske problemer.
Nærmere bestemt tar vi gjennom vårt forskningsprogram innen beregningsorientert biologi sikte på å skape en bedre forståelse av hvordan genuttrykket (dvs. når og hvor gener blir uttrykt) reguleres, og hvilke mekanismer som kan føre til forstyrrelser i denne reguleringen i sykdommer som for eksempel kreftr.
Hva arbeider du med i øyeblikket, og hva håper du å finne ut med forskningen din?
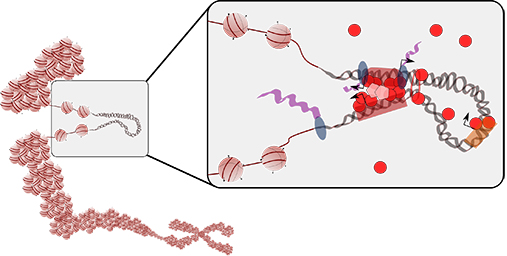
Det er et mål å tilby mer skreddersydd behandling i fremtiden. I den forbindelse er det helt avgjørende å forstå hvordan mutasjoner kan utløse sykdom hos enkeltindivider. Takket være høykapasitets sekvenseringsteknikker (også kjent som neste generasjon sekvenseringsteknikker) har vi større muligheter enn noensinne til å studere det menneskelige genom i et sykdomsperspektiv. Mens de fleste studier til nå har fokusert på regioner av det menneskelige genom som koder for proteiner (og som bare representerer ca. 2 % av hele genomet), prøver vi å forutsi hvilke mutasjoner i cis-regulerende DNA-regioner (brytere som regulerer når og hvor gener blir transkribert fra DNA til RNA) som fører til sykdommer.
Transkripsjonsfaktorer (TF-er) er viktige proteiner som binder seg til disse bryterne og kontrollerer når, hvor og i hvilken grad gener blir transkribert. Det har blitt vist at mutasjoner i TF-bindingsseter kan endre genuttrykket og utløse sykdommer som kreft hos mennesker. Forskning innen beregningsorientert biologi er avhengige av høykvalitetsdata, og vi har en god forståelse av dette. Derfor arbeider vi for tiden med å kombinere store mengder eksperimentelle data med egne beregningsmodeller for å identifisere bindingssetene for transkripsjonsfaktorer. Målet er å lage et kart som viser hvor TF-er binder seg til det menneskelige humane genom, og slik legge til rette for videre studier.
Neste trinn i arbeidet nå er å kombinere helgenomsekvenserings- og genuttrykksdata fra prøver fra kreftpasienter med vårt høykvalitets reguleringskart. Dette vil bidra til at man bedre kan forutsi hvilke følger mutasjoner kan ha i form av dysregulert genuttrykk og kreft.

Hvor tror du ditt forskningsfelt vil være om ti år?
Da jeg begynte på doktorgraden min for ca. ti år siden, hadde ikke universitetet mitt (Paris 6, Frankrikes største universitet) engang et institutt for bioinformatikk. I dag er det vanskelig å finne et biologirelatert senter eller institutt helt uten bioinformatikk. Feltet har altså vokst raskt i løpet av noen få år, men jeg tror vi fortsatt bare har sett begynnelsen.
Store mengder biologiske data genereres av enkeltlaboratorier og store konsortier i dag, og det er derfor et stort behov for beregningsverktøy og analysemetoder. Dette behovet vil bare bli større i årene som kommer, etter hvert som enda bedre teknologi driver kostnadene ned. I tiåret som kommer, tror jeg det vil bli behov for en bioinformatiker i alle biologiske laboratorier.
Noe av det som er mest spennende med beregningsorientert biologi, er at det per definisjon er et tverrfaglig felt. Bioinformatikk-, matematikk-, informatikk-, biostatistikk- og biovitenskapsmiljøene samarbeider allerede tett om å tolke biologiske data med direkte følger for pasienters liv. Dette samarbeidet kommer bare til å bli enda tettere i årene som kommer. Bioinformatiske verktøy er også helt avgjørende for at man skal klare å tilby skreddersydd behandling. Leger og klinikere må ha slike verktøy for at de skal kunne gi pasientene optimal behandling.
Fortell oss litt mer om hva du gjorde før du begynte å arbeide ved NCMM
Da jeg var ferdig med mastergraden min i informatikk, begynte jeg i 2006 på en doktorgrad ved det franske universitetet Paris 6 med dr. Alessandra Carbone som veileder. Hovedfokus i arbeidet mitt var å utvikle beregningsverktøy som kan forutsi korte RNA-sekvenser (mikro-RNA) involvert i den posttranskripsjonelle reguleringen av genuttrykk, dvs. i reguleringen av produksjonen av proteiner fra RNA-molekyler. Jeg flyttet deretter til Vancouver i Canada i 2011 for å bli postdoktor hos dr. Wyeth Wasserman ved University of British Columbia. I mer enn fem år utviklet jeg beregningsmodeller som skulle forutsi hvor transkripsjonsfaktorer binder seg til DNA-et for å regulere transkripsjonen av DNA-et til RNA. Så jeg har brukt de siste ti årene på å utvikle beregningsmodeller og -verktøy som kan brukes til å finne ut hvordan genuttrykk reguleres.
Hva ville du drevet med hvis du ikke hadde arbeidet innen forskning?
Det er vanskelig å si hva jeg ville gjort hvis jeg ikke hadde drevet med forskning. Da jeg begynte å studere, tenkte jeg på å bli mattelærer. Men så oppdaget jeg informatikk og ble veldig interessert i det, og deretter oppdaget jeg beregningsorientert biologi. Jeg syns det er spennende med tverrfaglighet og internasjonale miljøer. Nå som jeg arbeider innen beregningsorientert biologi, er jeg så heldig å få begge deler.
Hva har vært det største øyeblikket i karrieren din så langt, syns du?
Det var et stort øyeblikk da jeg fikk publisert min første artikkel. Men jeg er også stolt av å ha etablert min egen forskningsgruppe her ved NCMM. Det føles bra å samarbeide med, og veilede, talentfulle, hardtarbeidende forskere, og å bidra til vitenskapelige fremskritt.
Fortell oss litt mer om den nye seminarserien deres
Vi lanserer nå seminarserien «Sven Furberg Seminars in Bioinformatics and Statistical Genomics» i Oslo. Den er et resultat av et samarbeid mellom Geir Kjetil Sandve og Torbjørn Rognes fra gruppen Biomedisinsk informatikk, Arnoldo Frigessi fra Oslo senter for biostatistikk og epidemiologi, og meg selv, som arbeider ved NCMM. Fra 16. mars vil det bli avholdt månedlige seminarer, der kjente internasjonale forskere presenterer egen forskning innen beregning og statistikk med anvendelse på molekylærbiologi.
Hvert seminar vil være en enestående anledning til å høre på – og snakke med – sentrale forskere i feltet. Vi antar at publikum vil bestå av lokale informatikere, statistikere, matematikere og biologer som er interessert i utvikling og anvendelse av beregningsmessige og statistiske metoder og verktøy for analyse av molekylære data. Tanken med disse fellesarrangementene innen bioinformatikk og biostatistikk er å fremme fremragende forskning og lokalt og internasjonalt samarbeid.